Distilling JRuby: The JIT Compiler
The JIT compiler in JRuby is a relatively new creation for JRuby. Of course, the initial approach taken for the JRuby platform was the most straightforward: parse and interpret the code incrementally as the program executes, traversing the AST. As time went on, the JRuby team have taken a bunch of steps to improve the performance of JRuby, most of which have involved shortcutting the consistent, but also slow and indirect interpreter model. The JIT compiler is probably one of the most aggressive and technically complex steps taken to date.
JIT compilers are a novel idea: take some code in an “intermediate form”, and, given some heuristics, compile it into a “more native” representation, with the expectation that the more native version will perform faster, and allow for more optimizations by the underlying platform. If some optimizations can be thrown into the more native form in the process, all the better.
Java, as an example, has had a JIT compiler for several years now. In fact, Java was, for many developers, the first time they heard the term JIT; so much so that many developers I know think the “J” in JIT stands for “Java”. In fact, JIT stands for Just-In-Time. Smalltalker’s may recognize the term “Dynamic Translation” instead.
Anyway, when the Java runtime determines code is eligible for native compilation (frequency of execution is one of the primary parameters), it diverts the execution of the code, so it can perform some fancy hoop-jumping to turn the Java bytecode into platform-specific native instructions, thereby removing any cost of bytecode interpretation, and also throwing some nifty optimizations into the compiled code. From that point forward, the native code will be used for execution, unless and until it has been invalidated by changing assumptions.
JRuby’s JIT compiler is similar in nature, the primary difference being the source and destination formats. In Java the source format is Java bytecode, and the destination format is native machine instructions. Conversely, in JRuby, the source format is the JRuby AST, and the destination format is Java bytecode. Perhaps the most fascinating aspect of the JRuby JIT compiler is that it benefits from both the initial compilation into Java bytecode, and then later, when Java may attempt to translate the JRuby-generated bytecode into native machine instructions. So effectively, it is possible to get a double-JIT on your executing code.
Generating Java bytecode from interpreted Ruby code is no small feat, however; so, without further ado, let’s start the tour of JRuby’s JIT!
Article Series
- Distilling JRuby: Method Dispatching 101
- Distilling JRuby: Tracking Scope
- Distilling JRuby: The JIT Compiler
- Distilling JRuby: Frames and Backtraces
There’s Compilers, and then there’s Compilers #
Before we go to deep, we should do a quick overview of what is really meant by “compiling” in JRuby. Some of this discussion isn’t specific to the actual concept of “JIT” compilation; there are a few different code-paths to getting to compiled code in JRuby. One of those is definitely Just-In-Time method compilation, however JRuby can compile entire scripts as well (with Modules and Classes, and other fancy-shmancy stuff). So as this article proceeds, I will try to make a distinction on this.
When I refer to the JIT Compiler, I’m really referring to the component that is responsible for tracking method invocations and compiling them when appropriate. On the flip side, the term “Compiler” by itself belongs to the component in JRuby that can compile any Ruby script into an executable chunk of Java.
There are several tuning parameters in JRuby for the compiler as well; setting the maximum number of methods to compile, how many method calls before the compiler should be invoked, the maximum lines to compile into a single string of bytecode, etc. These settings affect different parts of the infrastructure, but for the most part, you shouldn’t have to care whether it is JIT-specific or not; in most cases it doesn’t matter.
Stay Classy, Java #
So, JRuby is compiling Ruby into executable chunks of Java - that much we know; but what are they, actually? Java, as you may or may not be aware, prevents the modification of any loaded classes in the VM (security or some such nonsense; dang buzzkills). This rule prohibits JRuby from using the same class file to represent a live class in Ruby. Intuitively, it might seem logical for JRuby to group all of the methods for a single Ruby class into a single Java class; however, because of the aforementioned restriction in Java, and the facts that a.) Individual method are only compiled by the JIT at thresholds (meaning some of a class may be compile-eligible, while other parts aren’t), and b.) Ruby allows for runtime method manipulation, this single-class paradigm isn’t possible. So instead, the JRuby-to-Java compiler infrastructure is designed to turn any given JRuby AST into a generated Java class. In other words, any time a hierarchy of AST nodes that represents a Ruby script is compiled in JRuby, a new Java class is derived to match, built, loaded, and otherwise made awesome. Unlike the actual meta-class in Ruby, the AST is as static as the block of code from which it was built. If another script comes along with more AST that modifies the same class, Ruby doesn’t care - it will simply have compiled method hooks pointing to two entirely different Java classes.
The classes generated by the JRuby compiler (note I didn’t mention the word JIT here), implement the JRuby interface ‘org.jruby.ast.executable.Script’. We’ll see later how this is actually used.
That’s Some Crazy JIT! #
In the first Distilling-JRuby article I detailed the class ‘DynamicMethod’. This class represents the “implementation” of a method in JRuby. As I discussed in that article, there are a ton of implementations; Figure 1 is the class-hierarchy again for those of you who’d rather not dig back to the old article. One of the arrows I have drawn on the diagram is pointing to an innocuous little class called ‘JittedMethod’. What this really represents is the cusp of the rabbit hole we are about to go down. Before we go too far down that hole, however, let’s do a quick recap.
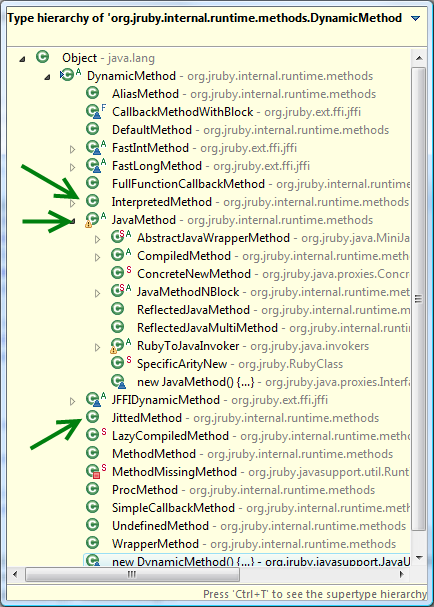
When JRuby wants to invoke a method, it has to find an implementation of that method. I talked all about that in part 1. When it finally does find that implementation, it is going to be one of these DynamicMethod objects. One of them that I mentioned previously is the “DefaultMethod”, which I referred to as the ‘shell game’ method implementation. DefaultMethod is a consistent implementation for callers that internally delegates to one of two implementations: InterpretedMethod (ol’faithful) and JittedMethod (a primary patient for today).
Method invocation is the point at which code is JIT’ed in JRuby (but not the only way it gets compiled). DefaultMethod keeps an internal counter representing the call-count for that particular method. This number will be used by JRuby to determine whether or not the method is “JIT eligible”. There are somewhere between ten and four million overloaded variants (I got tired of counting) of the ‘call’ method on DefaultMethod, but needless to say they all do something like this:
@Override
public IRubyObject call(ThreadContext context, IRubyObject self, RubyModule clazz, String name, [...]) {
if (box.callCount >= 0) {
return tryJitReturnMethod(context, name).call(context, self, clazz, name, [...]);
}
return box.actualMethod.call(context, self, clazz, name, [...]);
}
(In this case, “box” is just a container for the delegate method and the call count integer pair, and the […] denotes where the various “Arity”-supporting implementations diverge.)
s long as call count is a positive integer, the “tryJitReturnMethod” call is made, which will check in with the JIT subsystem, and will attempt to build a new method implementation. When that call completes, it returns a method implementation which this method can use, and that implementation is then invoked. If call count is negative, however, the method cached on this receiver is simply called.
The call-count integer serves multiple purposes. By simply being set negative, it effectively turns off the attempts to JIT-compile this particular method, but it also represents a counter for the number of invocations this method receives prior to JIT compilation actually being attempted. Call count is the primary metric JRuby uses to throttle JIT compilation.
The “tryJitReturnMethod” simply looks up the JITCompiler implementation using a call to Ruby#getJITCompiler(). From here, we are entering the JIT universe.
“You are in a maze of twisty passages, all alike.” #
The actual org.jruby.compiler.JITCompiler class represents the heart of the entire JIT process. This class is the manager for the primary JIT compilation efforts (It is also one of JRuby’s registered MBeans - a topic I plan to discuss soon). The primary invocation point is a method called “tryJIT”, which takes the DefaultMethod instance we were just working with, as well as the method name and the current ThreadContext (there’s that context showing up again). From here, a number of contextual checks are made to see if this particular invocation is eligible for JIT:
- Is the JIT compiler enabled?
- Is the method call count above the threshold for the JIT?
- Is the JIT method-cache full?
- Has the method been excluded from JIT’ing?
After all of this, if the method still checks out, it’s time to begin the real fun of compiling (or at least, trying to). At this point I’m going to (temporarily) do some hand-waving, and let us all pretend that we’ve passed a bunch of JRuby AST to our magic fire-breathing compiler monster, and out the back-side we were given a bunch of Java bytecode that acheives the same result as the AST. To help with the transition, I have made a high-level diagram for this portion of the code.

Assuming you are still on board, remember that the goal at this point is to have a Ruby method be converted into a loadable chunk of Java code, so the bytecode we were given (which represents a Java class) needs to be loaded into a Java class at runtime. JRuby needs an efficient and ‘appropriate’ way to load the Script sub-classes into Java, and keep a handle on them so we can create new instances of our ‘method’-powering class.
The component ‘org.jruby.ClassCache’ performs both of these tasks, and is responsible for respecting the cache configuration parameters specified at startup. The method ‘cacheClassByKey(…)’ is called, and is given the bytecode from our fire-breathing monster. To load the class into the runtime, a small class called OneShotClassLoader is used, which as the name implies, is only used once. The classloader is a child of the primary JRuby class-loader (in the normal case, anyway), which means that the code generated in the script has visibility to all of the JRuby classes and dependencies (this will be important later). At the same time, it means that the class is isolated from the other scripts in its own classloading domain.
Interestingly, this class-cache does not actually hand out references to the class. It returns the class from the initial cache call, but then simply retains references to the classes in a weak-reference form, so that if a method goes out of scope (like if a call to ‘remove_method’ was made on a class), the reference will be dropped, and the cache will shrink by one. In other words, the primary goal of the cache is to act as a throttle, as well as an endpoint for JMX monitoring.
To create a key to represent the class in the cache distinctly S-expressions are used. A class called SexpMaker is given the various AST elements representing the method, and it in turn generates an S-expression that represents the method. If you ever want to get a good feel for the methods stored in the ClassCache during a Ruby program execution, putting a break-point and looking at the S-expressions in the cache can be enlightening. As an example, I created a very simple Ruby class that looked like this, and made a call to it in my script elsewhere:
class MyClass
def do_something
c = 3
d = c
end
end
# ...
obj = MyClass.new
obj.do_something
I then set up the JIT compiler to run in such a way that this method would be JIT’ed. Here is the S-expression generated for that method (formatting mine):
(
method do_something (argsnoarg) (
block
(newline (localasgn c (fixnum 3)))
(newline (localasgn d (localvar c)))
)
)
As you can see, it’s a short-hand representation of the actual AST, and it is unique for that AST structure.
Method Swapping #
So we’ve made it through the journey of the compiler, and our JIT’ed code is now contained in a nice handy-dandy Script class. The JIT compiler class proceeds to create a new instance of our Script, and along with some various bookkeeping, calls DefaultMethod.swithToJitted(Script, CallConfiguration), passing in the Script object that represents the logic for this method.
This method assigns a new JittedMethod object to the default method container, and sets the call-count to a negative value, disabling subsequent JIT attempts.
Assuming the compilation has worked correctly, the actual invocation of the script is fairly straightforward. There are a variety of ‘Arity’ implementations on the Script API to line up with the DynamicMethod call methods, but for the most part they all do the same thing:
try {
pre(context, self, name, block, 1);
return jitCompiledScript.__file__(context, self, [...]);
// handle exceptions omitted.
} finally {
post(runtime, context, name);
}
Effectively, the Script API is analogous to a general ‘Runnable’ representing a block of code; it has been specialized to handle a number of call configurations, but for the most part, it simply is a logic containing object.
From this point forward, that method is now JIT’ed unless/until it is removed from scope.
I’d Like a Side of Bytecode With My Bytecode #
Okay, time for the good stuff. We’ve done enough hand-waving, it’s time to explore the compiler. Before I go any further, I should mention the –bytecode switch. If you ever want to see the bytecode JRuby generates for a chunk of Ruby code, you can simply by invoking JRuby:
jruby --bytecode my_script.rb
It was immeasurably helpful to me in writing this article.
Compiler Components #
There are several pieces and parts that all participate in the compilation process (and incidentally, many have the word ‘compiler’ in the name). That makes it a fairly complex creature to understand. If the compiler is a big furry fire-breathing monster, we’re about to dissect it and poke at the internal organs. So, let’s start with a quick break-down:
-
org.jruby.compiler.ASTInspector - The ASTInspector class is effectively a statistics-gathering tool for the AST; a detective looking for certain conditions. The AST is given to this class at the start of compilation, and it looks for certain conditions in the AST that influence the overall behavior of the resulting code. One of those conditions that is scanned for is the concept of scope (which #{post ‘distilling-jruby-tracking-scope’}we talked about last time#{/post}). Scope becomes very important, because if the code in question doesn’t need an explicit scope, the compiled code can be made much simpler; likewise if it does have some intense scoping, the compiled code has to make sure it respects that so variables aren’t leaking all over the place.
-
org.jruby.internal.runtime.methods.CallConfiguration - This is an enumeration representing the type of method invocation involved at a certain level, and is calculated and returned by the ASTInspector, depending on the structures it finds. The call configuration isn’t unique to the compiler process; in fact it really is part of the scope management; but was a bit too detailed for the previous discussion. This enumeration is the actual object that performs the ‘pre/post’ invocations on the ThreadContext to setup any scope that is necessary; different work is done depending on the requirements of method being invoked. Some example call configurations are FrameFullScopeFull (meaning it needs a frame and a scope) and FrameNoneScopeNone (meaning it needs neither). We haven’t discussed the concept of ‘frame’, however it basically represents the invocation of a method in a certain context: the call frame. It keeps track of information that allows Ruby to manage the call stack beyond the scope, which we previously discussed.
-
org.jruby.compiler.ASTCompiler - The ASTCompiler knows specifically how to traverse the AST, and how to then consult with other objects to translate it into an alternate representation. To handle the actual bytecode generation, the ASTCompiler hands responsibility off to the bytecode generating parts. The ASMCompiler handles the busy work of setting up the compiler hierarchy when traversing method entry/exit, closures, etc.
-
org.jruby.compiler.ScriptCompiler - The ScriptCompiler interface defines the high-level hooks into the underlying bytecode generation process used by the ASTCompiler. The sole implementation of this API currently is StandardASMCompiler, which as you could guess is backed by the ASM bytecode library This class will create “sub-compilers” that know how to deal with the recursive nature of the compilation process.
-
org.jruby.compiler.impl.BodyCompiler - BodyCompilers are the ‘sub-compilers’ I just mentioned. Specifically, each BodyCompiler deals with blocks of code that may carry their own scope/set-of-variables (good thing we already discussed scope!). Here is the current class-hierarchy of body compilers:
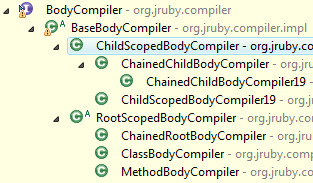
The two primary categories are “root-scoped” and “child-scoped”. In our scope discussion, we called these two scenarios “local” and “block” respectively. Here is the root-scope javadoc:
/** * Behaviors common to all "root-scoped" bodies are encapsulated in this class. * "Root-scoped" refers to any method body which does not inherit a containing * variable scope. This includes method bodies and class bodies. */ -
org.jruby.compiler.VariableCompiler - The variable compiler API knows how to generate bytecode for loading and storing variable values from the Ruby runtime. Body compilers create variable compilers appropriate for their scope. Certain scope rules allow for certain optimizations which will be described below.
-
org.jruby.compiler.InvocationCompiler - The invocation compiler is a component that knows how to generate bytecode for invoking methods on Ruby objects in the Java memory space. All body compilers have these. This will be described in more detail below.
-
org.jruby.compiler.CacheCompiler - Compiler that can translate certain references in the Java bytecode into quick lookups on the AbstractScript.RuntimeCache object, rather than having to do full lookups into the Ruby runtime (for methods, fixnums, etc). This allows the JVM more opportunities for optimization via inlining and other good stuff.
-
org.jruby.compiler.impl.SkinnyMethodAdapter - Delegating implementation of the ASM MethodVisitor interface that has several convenience methods for making typed bytecode calls; this makes the code that is generating bytecode much easier to trace through than it otherwise would be (not as easy as Bitescript, but we can’t always be idealists).
Here is another view of these elements, roughly categorized by responsibility, showing some interactions:
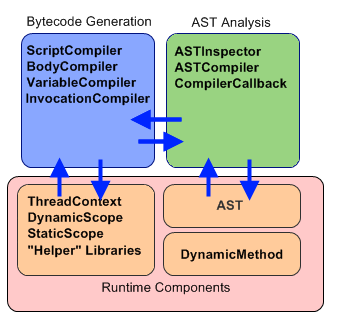
(This is only one of many ways to show the interactions at this level, however it should give you some idea of the segregation of these components by responsibility)
The AST analysis components work with the bytecode generation libraries to recursively build up a representation of the algorithm. In the process, the bytecode generation libraries are going to “wire in” to the bytecode calls into several JRuby runtime libraries, including many we’ve already seen, such as the ThreadContext, the scope objects, and a bunch of other helper libraries that are implemented as statics everywhere.
The Nature of the Generated Code #
As with everything in JRuby, there are all kinds of special fast-path hooks built into place that complicate the code for quick scanning, however we can talk about the “general” case first, and work our way into the special cases. With our previous code walkthroughs, we saw that the interpreted AST code performed the invocation using a combination of recursive node traversal and invocations of calls into the ThreadContext to manage and lookup scoped variables (creating scopes, storing values, etc). The generated code often stores and retrieves variable values the same way as we have already discussed - via collaborative lookups on the current dynamic scope. In other words, let’s say we have this method:
a = 5
b = a
At this point, it’s going to be easier for me to write pseudo-Java-code to express what the generated code could do to solve certain problems. Remember that JRuby is generating Java bytecode to effectively do the same thing I’m doing here.
The pseudo-Java for this particular example could look something like this:
ThreadContext.getCurrentScope().setValue("a", new RubyFixnum(5));
ThreadContext.getCurrentScope().setValue("b"), ThreadContext.getCurrentScope().getValue("a"));
Now, I took several liberties with this code to make it easier to read (this isn’t valid code), but it should look a lot like the API we discussed previously in the scope article. In fact, this is the general idea of the code that is generated in many cases by JRuby. It gets more complicated than this, obviously, but this shows the most naive implementation of the JIT compiler - basically: turn the steps taken at runtime by Ruby into hard-wired Java.
If we start poking through the various compilers, we’ll see that they often make extensive use of the Ruby libraries that the AST uses (as we would expect). Here is an example from the HeapBasedVariableCompiler.assignLocalVariable(int index) method (we’ll analyze the variable compilers more deeply below):
method.aload(methodCompiler.getDynamicScopeIndex());
method.swap();
method.invokevirtual(p(DynamicScope.class), "setValueZeroDepthZero", sig(IRubyObject.class, params(IRubyObject.class)));
In this case, “method” is a SkinnyMethodAdapter object as described above. This method is telling the current enclosing Java method to load the DynamicScope object from the local variable table, swap the “value to set” back onto the top of the stack, and then invoke the “setValueZeroDepthZero” method on it (which is a hardwired method for setting the variable at position 0, depth 0 with a value). That means that the DynamicScope variable has to be somewhere on the local variable stack (we’ll see how below), but beyond that it’s fairly straightforward (as these things go, anyway).
Stack vs. Heap #
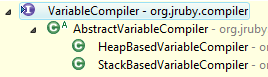
All of this talk about DynamicScope and looking up variables is a bit over-simplified. The JRuby JIT compiler has support hard-wired into it for dealing with variables exclusively on the local stack. This is provided via the StackBasedVariableCompiler (you can see the variable compiler hierarchy here). The various body compilers (which, if you recall, represent methods, classes, blocks, and so forth) checks with the associated ASTInspector. If the inspector says that there is no special use of closures or scope-aware method calls, the scope will then create a special stack-based variable compiler.
This stack-based variable management is a pretty significant optimization. Java is much more efficient when dealing with stack-based variables as opposed to heap references, stack memory access is bound to be faster. In interpreted JRuby execution mode there is no such thing as a stack-based Ruby variable; all of the variable tracking is synthesized by the JRuby runtime via use of the Java heap and the scope objects we previously discussed.
Here is what the local-variable assignment looks like for the stack-based variable compiler:
method.astore(baseVariableIndex + index);
We’ve dropped the DynamicScope lookup, not to mention the invokeVirtual on dynamic scope. In this particular scenario, we have entirely bypassed the JRuby libraries altogether, and are simply using native Java stack to track the Ruby object/value instead. In this particular scenario, JRuby has managed to convert an operation into the direct Java counterpart, with no compromises. That is, of course, lightning fast variable assignment (much faster than several hops through methods in the DynamicScope, and doing in-heap array lookups, etc).
One of the things that the VariableCompilers are responsible for is setting up variables at the start of a method or closure. There are a number of methods on the VariableCompiler API that are consulted at the introduction of these top-level elements - here are three of those elements:
public void beginMethod(CompilerCallback argsCallback, StaticScope scope);
public void beginClass(CompilerCallback bodyPrep, StaticScope scope);
public void beginClosure(CompilerCallback argsCallback, StaticScope scope);
The HeapBasedVariableCompiler is going to get all of the lookup objects it needs (most notably, the DynamicScope) and stuff them into the method as local variables. More concretely, at the top of the heap-generated methods in JRuby, the bytecode generated by ‘beginMethod’ looks something like this:
public IRubyObject __file__(ThreadContext ctx, IRubyObject self, [...]) {
DynamicScope scope = ctx.getCurrentScope();
// actual algorithm goes here
}
(I feel the need to re-stress that this Java code is my extrapolation of the compiled bytecode - JRuby does not currently actually generate Java source, and instead has the “luxury” of dealing with Java bytecode variable indexes and the like. If you were to decompile the bytecode, it might look a little something like this, however.)
There are, of course, other things that the heap-based variable compiler may choose to do at this point to optimize itself, but those specifics aren’t particularly relevant to the idea. If you go back to our “a=5; b=a” example, you’ll see that the pseudo-Java can then simply reference ‘scope’, as opposed to calling ctx.getCurrentScope() every time.
On the other side of the fence, the StackBasedVariableCompiler (which knows it can deal with variables entirely on the Java stack), loops over all of the variables and declares them at the top of the method, assigning them to JRuby ’nil’. In this example, if the method is going to deal with three variables (we’ll call them ‘a’, ‘b’, and ‘c’), then the stack-based compiler would start the method like this:
public IRubyObject __file__(ThreadContext ctx, IRubyObject self, [...]) {
Object a = ruby.getNil();
Object b = ruby.getNil();
Object c = ruby.getNil();
// actual algorithm goes here
}
This allows the subsequent code to just deal with variable declaration implicitly, just like Ruby does - since the variables are already on the Java stack, they can simply be blindly assigned a value by the rest of the native bytecode - so going back to our ‘a=5;b=a’ example, it is not unreasonable to consider JRuby generating another set of lines that looks like this:
a = new RubyFixnum(5);
b = a;
Not too shabby! In reality, JRuby can optimize even further than this (like dealing with fixnums smarter than that), but that’s beyond this discussion.
Invocation Compiler #
The InvocationCompiler is responsible for create bytecode that can invoke another method. In the current JDK world, that means loading the appropriate variables on the stack to then invoke the method “IRubyObject.callMethod(…)” on the “receiver” object. In other words, if the Ruby code was:
a.do_something
The pseudo-Java code we want to generate would look something like this:
IRubyObject a = // ... (from somewhere)
IRubyObject result = new NormalCachingCallSite("do_something").call(a);
Of course, this is a major simplification of the actual call-site management provided by the invocation compiler, and all of this actually implemented in scary bytecode, but you get the idea. From here, the Ruby runtime takes over the method invocation, which goes through the DynamicMethod dispatching we’ve previously discussed. In that process, it may compile more code and create more class-files, but they are effectively disconnected from each other via the call-site indirection through the Ruby runtime method dispatching.
In the “amazing future” we have the concept of “invokedynamic”, which is a Java 7 bytecode instruction that allows for invocations to dynamically-generated methods in the Java space, allowing a language like Ruby to hook into the JVM’s method dispatching, in turn allowing method dispatching in the JIT-compiled code to be fully optimized. Charlie Nutter has described this far better than I can, and his article ties in nicely with the method dispatching I previously discussed.
How JIT Participates #
The JITCompiler class effectively has to ‘jump in the middle’ of this compilation routine - taking a single Ruby method and translating it into an entire JIT-compiled class. The class JITClassGenerator (an inner-class to JITCompiler) is responsible for handling this special scenario.
Remember, we already have all of these concepts built for compiling arbitrary scripts - the ASTCompiler and ScriptCompiler are fully capable of handling the introduction of a method. Therefore, most of the work actually happens via the ScriptCompiler. Where-as the general compilation will make calls to “compileRoot” or “startRoot” - the JIT process makes calls to “startFileMethod”.
The primary distinction between the two invocations is described in the ScriptCompiler Javadocs:
/**
* Begin compilation for the root of a script named __file__.
*
* @param args Arguments to the script, as passed via jitted wrappers
* @param scope The StaticScope for the script
* @param inspector The ASTInspector for the nodes for the script
* @return A new BodyCompiler for the body of the script
*/
public BodyCompiler startFileMethod(CompilerCallback args, StaticScope scope, ASTInspector inspector);
/**
* Begin compilation for a the root of a script. This differs from method compilation
* in that it doesn't do specific-arity logic, nor does it require argument processing.
*
* @param javaName The outward user-readable name of the method. A unique name will be generated based on this.
* @param arity The arity of the method's argument list
* @param localVarCount The number of local variables that will be used by the method.
* @return An Object that represents the method within this compiler. Used in calls to
* endMethod once compilation for this method is completed.
*/
public BodyCompiler startRoot(String rubyName, String javaName, StaticScope scope, ASTInspector inspector);
Basically, startFileMethod performs a special pre-configuration on the generated class to make is self-sufficient for this single method, and entirely invokable through the ‘Script.run’ API. The JITClassGenerator is going to exercise the ASTInspector on the top-level of the method (just like the ASTCompiler would when it hits a method), and is going to then pass all of that information into the ScriptCompiler for construction.
From that point forward, the method is digested as it normally would be by the recursive inspection/compilation process.
Compiler Cookbook #
At this point in this article, the general concepts have been thoroughly hashed out, but we’re simply missing some examples of what Java is actually built when certain scenarios are hit. So let’s walk through some. I’m going to use the same scheme from above, describing at a high-level the code that JRuby generates, and then possibly using pseudo-Java examples.
General AST Class
We’ve talked about it quite a bit already, but to cement things - if you have a ’test.rb’ script and you compile it, you’re going to get back a class representing that script. The most natural Java code representation looks something like this:
public class test extends org.jruby.ast.executable.AbstractScript { // implements Script indirectly
public test() {
// some basic initialization here
}
public IRubyObject __file__(...) {
// top-level script code here
}
}
There is, of course, other stuff that goes on. But that’s the general ‘framework’ in which the rest of the generated code works.
Creating a Method
Generally speaking, Ruby methods are translated into Java methods. However, where-as the Ruby methods are typically associated with some parent class, in Java they are simply on the Script-class for which they are compiled. When a method is hit, Ruby combines all of the stuff we previously discussed to create that method. Let’s consider this Ruby script:
def my_method
a = 5
b = a
end
my_method
JRuby is going to declare the method, embed the logic, and then invoke it. In this particular case, JRuby will be able to use stack-based variables. Let’s build on our previous class (trimming some of the irrelevant bulk):
class test extends AbstractScript {
@JRubyMethod(name="my_method", frame=true, ...)
// not the actual generated method name, but close.
public IRubyObject RUBY$my_method(ThreadContext ctx, IRubyObject self) {
Ruby r = ctx.getRuntime();
Object a = r.getNil();
Object b = r.getNil();
a = RubyFixnum.five;
b = a;
return b;
}
public IRubyObject __file__(ThreadContext ctx, IRubyObject self) {
RuntimeHelpers.def(ctx, self, this, "my_method", "RUBY$my_method", new String[] { "a", "b" }, ...);
// in reality, this would be cached by the CacheCompiler, but for ease-of-reading, I'm creating a new one here.
return new VariableCachingCallSite("my_method").call(ctx, self, self);
}
}
Wow, a lot going on here - let’s break it down.
- First, we create a Java method as a peer to a Ruby method. We also assign an annotation to it so it can be tracked in a number of ways by the running system. The method name is generated; I’ve simplified it slightly here, but you get the idea.
- Then, using the logic we’ve discussed previously regarding the variable management, our method body is compiled and has a rough sketch of what we did with A and B in the ruby implementation.
- The file method (which represents the invokable part of the script) is created, and is invokable through the Script API
- file declares our method first. It uses a static call to RuntimeHelpers to do this, which basically looks up the class, and stuffs in a new DynamicMethod object into the RubyClass definition that can call into this script. (Keep in mind in the JIT scenario, this ‘declaration’ is skipped, and instead the body of the method is compiled into the file method, which is then referenced inside a JittedMethod object).
- Next, we get a handle on a CallSite object, and then call invoke on it. From here, Ruby is going to wind back through the call-process to our compiled method object we just put in the RubyClass.
Naively, this invocation can use reflection to make the call. However, remember from the first discussion that call-site objects often result in pre-compiled “mini-classes” that have a single purpose - calling the method on an object. These mini-classes can often be jitted out of the execution, making our indirect call-site invocation nearly as fast as a direct method call - cool!
Creating a Class
Class creation in Ruby scripts is not necessarily creation (it could be augmentation/modification). As such, creating a Java Class is not actually what needs to be done in this case. Besides, even if the class is created in a compiled script, it still needs to be in the JRuby class namespace so that non-compiled code can reference it. Therefore, a method is created that can perform the class construction. Here’s a basic modification of our example:
class MyClass
def my_method
a = 5
b = a
end
end
x = MyClass.new
x.my_method
Our example grows again in this case:
class test extends AbstractScript {
public RUBY$MyClass(ThreadContext ctx, IRubyObject self) {
RubyModule m = RuntimeHelpers.prepareClassNamespace(ctx, self);
RubyClass cls = m.defineOrGetClassUnder("MyClass", null);
LocalStaticScope scope = new LocalStaticScope(...); // for the class
ctx.preCompiledClass(scope, ...);
try {
RuntimeHelpers.def(ctx, self, this, "my_method", "RUBY$my_method", new String[] {"a", "b"});
}
finally {
ctx.postCompiledClass();
}
}
@JRubyMethod(name="my_method", frame=true, ...)
// not the actual generated method name, but close.
public IRubyObject RUBY$my_method(ThreadContext ctx, IRubyObject self) {
Ruby r = ctx.getRuntime();
Object a = r.getNil();
Object b = r.getNil();
a = RubyFixnum.five;
b = a;
return b;
}
public IRubyObject __file__(ThreadContext ctx, IRubyObject self) {
DynamicScope scope = ctx.getCurrentScope();
RubyClass cls = RUBY$MyClass(ctx, self); // invoke the class-creation method.
// in reality, this would be cached by the CacheCompiler, but for ease-of-reading, I'm creating a new one here.
scope.setValue("x", new NormalCachingCallSite("new").call(ctx, self, cls));
return new NormalCachingCallSite("my_method").call(ctx, self, scope.getValue("x"));
}
}
So what’s changed since our basic method-only example? Well, the generated “my_method” is identical. However, we now have a method to create the class as well. Let’s analyze this method:
- First, given the current context, find the appropriate RubyModule.
- Ask the module to get or define the class with the given name (remember, we could be updating an existing class.
- Adjust the ThreadContext to have the class as the primary scope.
- Define the method (which will be defined on the current class in scope).
- Reset the ThreadContext
If we look at our file method, you’ll see the first thing it does this time is call this “class constructor”. Note also that the file method is now using heap-based variable management because the AST has classes mixed in, causing the inspector to throw out stack-based management due to the risk of leaky vars.
After calling the construct method, the method then invokes setValue for the current scope, passing in the result of calling ’new’ on the new class. Then, the invocation of “my_method” is performed on the object held in “x” on the scope.
Other scenarios are just extensions of all of these same ideas.
Future Plans #
As fancy as this current compiler architecture is, the JRuby team is not sitting still. Currently in JRuby master, there is a significant effort underway to reimagine the underlying compilation process. One of the problems with the current approach is that the AST does not lend itself well to analysis and optimization. The current work underway derives a new intermediate representation from the AST, providing an entirely separate object hierarchy. This new representation can then be shuffled and reorganized; patterns can be derived and compressed, and all sorts of other gooey goodness can be found. The IR is designed to be analyzed by the compiler; something that could never be said for the AST.
From a component standpoint, the plan (as best as I have derived) is to replace the true “compiler” component as described above, allowing the higher-level constructs that embed that compiler into the JIT process, leaving the rest of the infrastructure around it (like the JITCompiler class) mostly unchanged.
In other words, much of the existing ASTInspector/ASTCompiler goes away, in favor of something that is more compiler-friendly - an IR scanner.
This new IR code structure will bring the JRuby JIT one step closer to what is possible in the Java JIT, where optimizations can be made by analyzing the code structure; entire branches of code (and the associated conditions) can be eliminated, loops can be optimized, etc. Of course, the options for what can be optimized in a Ruby program are often different than Java - some of the language differences could be advantageous for optimization, and some may cause serious limitations - time will tell, but I have confidence it will be interesting to see the results.
Nevertheless, the work is fairly new on this, and I’d hate to spend too much time analyzing and documenting a work in progress, but it is something to revisit in a few weeks/months. At a minimum, I suggest following the JRuby committer blogs (for a start: Charlie Nutter, Tom Enebo, Nick Sieger).
Conclusion #
This article was by far the longest yet, coming in well over 6000 words (and that means if you’ve read this far you are a patient, patient individual). Short of making this a “two-parter”, I’m not sure how I could have shortened it and truly hit the hotspots of the compilation process in Ruby; however I do think my next exploration might be a touch more ‘focused’.
I haven’t entirely decided yet what’s on the chopping block next for these JRuby internals articles, but I have a couple ideas; and of course, I’m always taking input at My Contact Page.
Stay tuned.